[NLP] LLM 서빙을 위한 VLLM 이란?
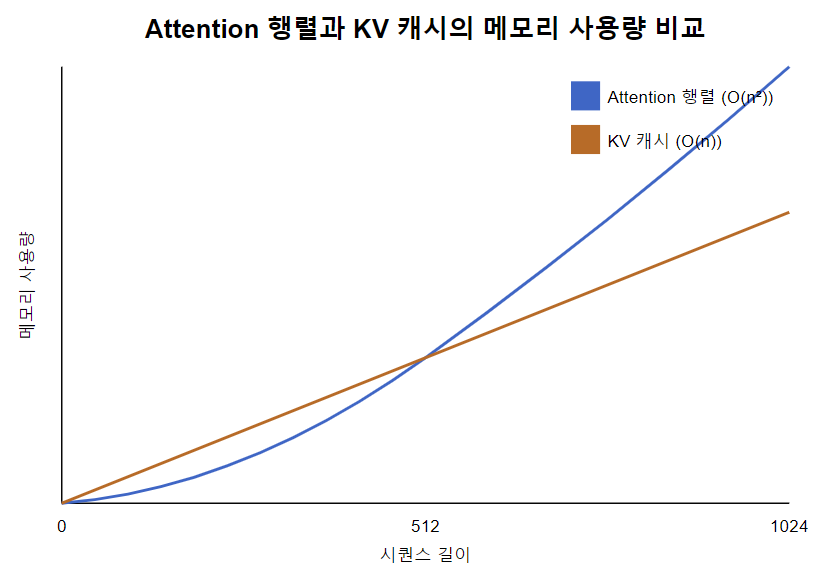
개요 기존 LLM 모델을 서빙하는 것에는 여러 문제점이 존재합니다. 모델 크기가 매우 커지면서 메모리 요구량도 증가했고, 애플리케이션에서의 빠른 추론 시간 요구량도 증가했습니다. 그렇다면 기존 LLM 추론 방식에는 어떤 한계가 있고 vLLM은 어떻게 이를 해결했을까요? 기존 LLM 추론 방식 긴 시퀀스 처리 시 메모리 사용량 급증 주요 메모...
개요 기존 LLM 모델을 서빙하는 것에는 여러 문제점이 존재합니다. 모델 크기가 매우 커지면서 메모리 요구량도 증가했고, 애플리케이션에서의 빠른 추론 시간 요구량도 증가했습니다. 그렇다면 기존 LLM 추론 방식에는 어떤 한계가 있고 vLLM은 어떻게 이를 해결했을까요? 기존 LLM 추론 방식 긴 시퀀스 처리 시 메모리 사용량 급증 주요 메모...
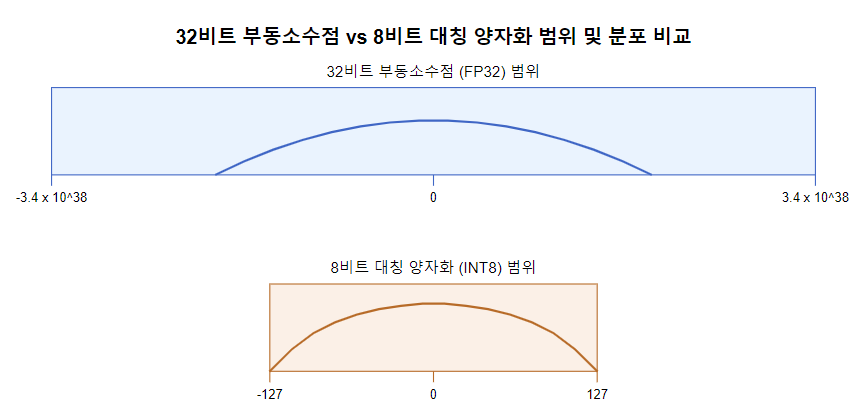
개요 최근 LLM의 모델의 크기는 기하 급수적으로 증가하고 있습니다. 단순한 예로, GPT-3는 1750억개의 파라미터를 가지고 있으며 이는 엄청난 양의 저장 공간과 메모리를 필요로 합니다. 이처럼 큰 모델은 추론 시 많은 계산 리소스를 필요로 하며, 이는 높은 운영 비용과 긴 처리 시간으로 이어저 사용자의 만족도를 떨어트리는 결과로 나타납니다....
콜봇 서비스를 개발하면서 Twillio란 플랫폼에 대해 알게되어 이렇게 정리해 보았습니다. Twilio는 클라우드 통신 플랫폼으로, 개발자들이 다양한 통신 기능을 애플리케이션에 쉽게 통합할 수 있게 해주는 서비스입니다. 어떻게 작동하는지, 번호 구매부터 Flask app과의 연동까지 함께 알아보도록 합시다. 번호 구매 홈페이지에서 좌측 ...

도입 오늘 리뷰할 논문은 Microsoft Research팀이 출간한 ‘From Local to Global A Graph RAG Approach to Query-Focused Summarization’입니다. 마이크로소프트 연구팀은 본 논문에서 기존 RAG 방법이 전체 데이터셋에 대한 글로벌 질문에 적합하지 않다는 문제를 정의하고, 이를 해결...

기존에 PC에 Docker와 Azur가 설치되어 있다는 전제로 다음을 진행한다. 1. Azure Container Registry(ACR) 생성 Azure Container Registry(ACR) 생성 가이드 Azure 포털(https://portal.azure.com/#home)에 로그인합니다. 왼쪽 상단의 메...
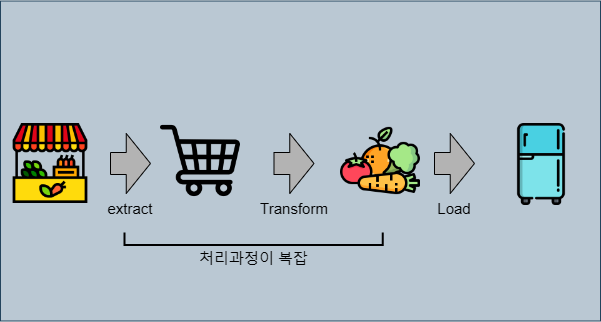
데이터 엔지니어링? 대규모 데이터를 효율적으로 수집, 저장, 처리, 분석할 수 있도록 하는 일련의 프로세스와 기술을 의미한다. JD 예시 ETL, ELT? 데이터를 처리하는 두 가지 접근 방식 ETL (Extract, Transform, Load): 데이터를 소스에서 추출하고, 중간 단계에서 변환한 후, 최종 목적지에 적재 마치...
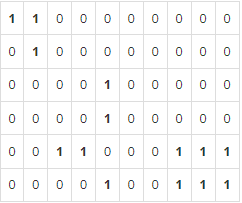
1012번 - 유기농 배추 https://www.acmicpc.net/problem/1012 왜 DFS? 문제의 핵심은 “연결된 배추 그룹”을 찾는 것이다. DFS를 사용하는 이유는 이러한 연결된 그룹을 효율적으로 찾기 위함이다. 1 2 3 4 5 6 7 8 9 10 11 #dfs 함수 def dfs(x, y): if x < 0...
완전탐색이란? 정의 : 가능한 모든 경우의 수를 빠짐없이 조사해 문제의 해를 찾는 알고리즘 기법 특징 : 모든 가능성을 고려하므로 항상 최적의 해를 찾을 수 있다. 문제의 크기가 작을 때 효과적이다. 구현이 비교적 간단하다. 시간 복잡도가 높아 큰 입력에 대해서는 비효율적이다. 주요 방법 : 부르트 포스(Brute Force)...
Breadth-First Search (BFS)란? 시작 정점으로부터 가까운 정점을 먼저 방문하고 멀리 떨어진 정점을 나중에 방문하는 탐색 방법이다. 동작 방식은 다음과 같다. 큐(Queue)를 사용해 구현한다. 시작 정점을 큐에 넣고 방문 표시를 한다. 큐에서 정점을 꺼내 그 정점과 인접한 모든 미방문 정점을 큐에 넣고 방문 표시를 한...
인접 리스트(Adjacency List)란? 인접 리스트(Adjacency List)는 그래프를 표현하는 또 다른 방법으로, 각 정점에 인접한 정점들을 리스트로 저장하는 자료구조를 의미한다. 정점 번호나 이름을 key로, 인접 정점들의 리스트를 value으로 저장한다. 희소(sparse)한 그래프에서 공간 효율적이다. 정점의 인접 정점을...