[NLP] LLM 서빙을 위한 VLLM 이란?
개요
기존 LLM 모델을 서빙하는 것에는 여러 문제점이 존재합니다. 모델 크기가 매우 커지면서 메모리 요구량도 증가했고, 애플리케이션에서의 빠른 추론 시간 요구량도 증가했습니다. 그렇다면 기존 LLM 추론 방식에는 어떤 한계가 있고 vLLM은 어떻게 이를 해결했을까요?
기존 LLM 추론 방식
긴 시퀀스 처리 시 메모리 사용량 급증
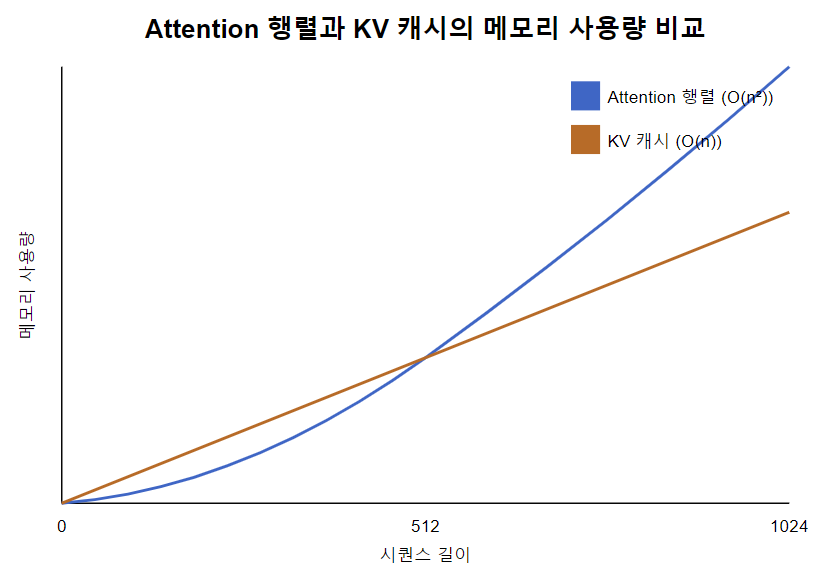
주요 메모리 사용량 급증의 주요 원인 두 가지는 아래와 같습니다.
- Attention의 행렬(시퀀스 길이 x 시퀀스 길이)
- self attention 메커니즘에서 각 토큰은 다른 모든 토큰과의 관계를 계산합니다.
- 시퀀스 길이에 따라 메모리 사용량이 이차함수적(N^2)으로 증가합니다.
- Key와 Value 캐시
- 현재 토큰의 Query와 모든 토큰의 Key를 사용해 어텐션 점수를 계산하는 과정에서, 이전에 처리된 모든 토큰의 key, value를 저장해야 합니다.
- 시퀀스 길이에 따라 메모리 사용량이 선형적(N*D)으로 증가합니다.
이는 긴 대화나 문서 처리 시 메모리 부족 문제가 발생하게 되며, 처리 가능한 컨텍스트 길이가 제한됩니다.
배치 처리의 비효율성

전통적인 배치 처리는 고정된 크기의 배치를 사용해, 다양한 길이의 입력을 효율적으로 배치 처리하기가 어렵습니다. 특히 패딩된 부분은 불필요한 연산을 수행하며 GPU의 활용도가 떨어지고, 처리량이 감소하며, 일부 요청의 지연 시간이 증가합니다.
vLLM의 특징
PagedAttention
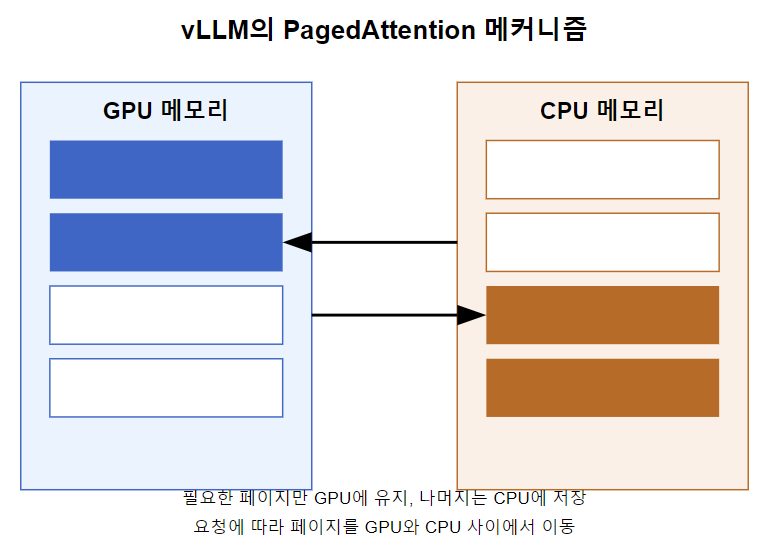
- KV 캐시를 고정 크기의 블록(페이지)으로 나눕니다.
- 필요한 페이지만 GPU 메모리에 유지하고, 나머지는 CPU 메모리에 저장합니다.
- 필요에 따라 페이지를 GPU와 CPU 메모리 사이에 이동시킵니다.
PagedAttention을 통해, 전체 KV 캐시를 GPU에 유지할 필요가 없어져, 제한된 GPU 메모리로도 매우 긴 시퀀스를 처리할 수 있게 되었습니다.
연속 배치 처리(Continuous Batching)
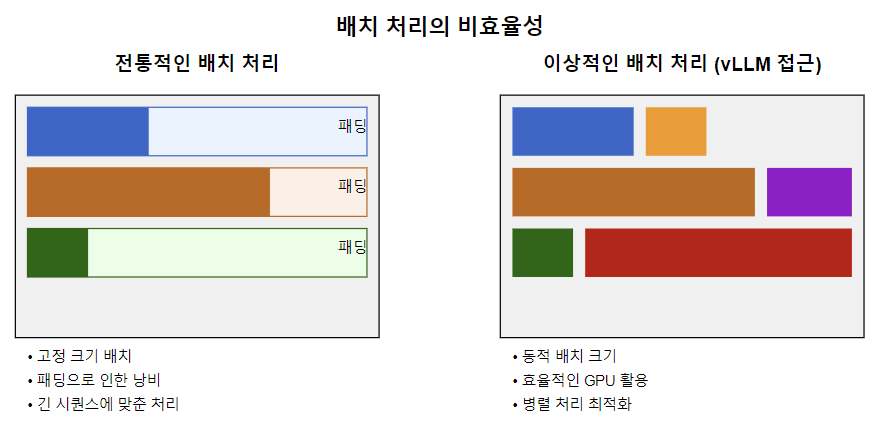
- 고정 크기 배치 대신, 동적으로 요청을 그룹화합니다.
- 다양한 길이의 시퀀스를 효율적으로 처리합니다.
연속 배치 처리를 통해, 패딩을 최소화하고 GPU 자원을 더 효율적으로 사용할 수 있게 되었습니다.
This post is licensed under CC BY 4.0 by the author.