[논문리뷰] From Local to Global A Graph RAG Approach to Query-Focused Summarization
도입

오늘 리뷰할 논문은 Microsoft Research팀이 출간한 ‘From Local to Global A Graph RAG Approach to Query-Focused Summarization’입니다.
마이크로소프트 연구팀은 본 논문에서 기존 RAG 방법이 전체 데이터셋에 대한 글로벌 질문에 적합하지 않다는 문제를 정의하고, 이를 해결하기 위해, LLM을 활용한 ‘지식 지도’를 만들고 글로벌 질문에 답하는 Graph RAG 방법에 대해서 설명합니다.
기존 RAG의 한계와 QFS
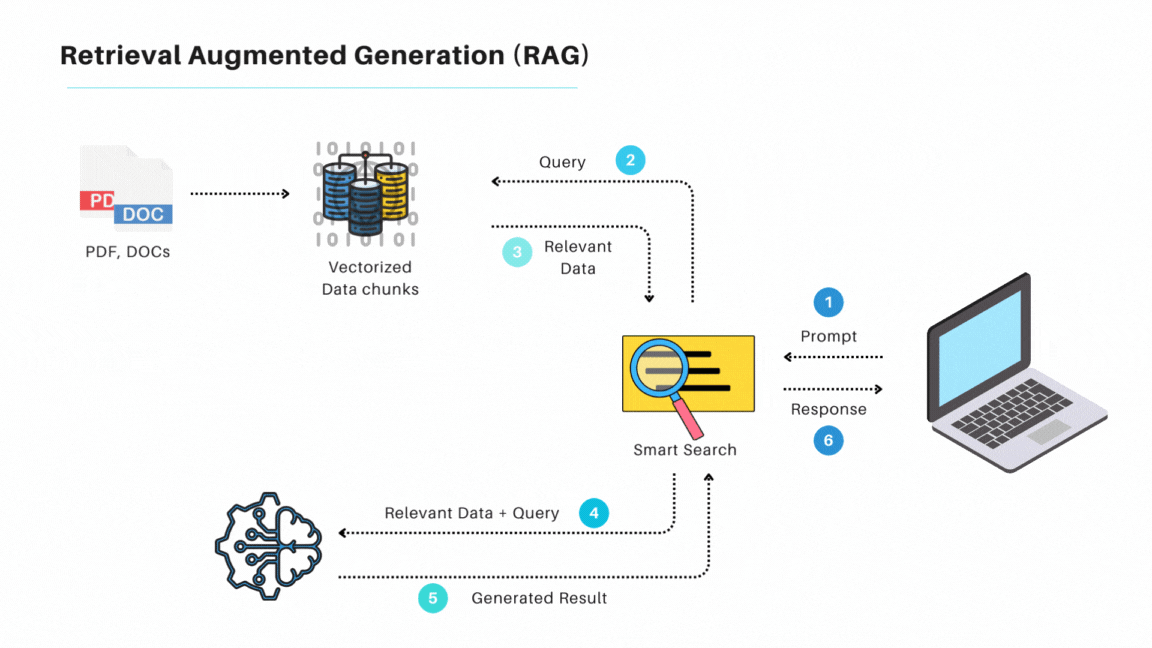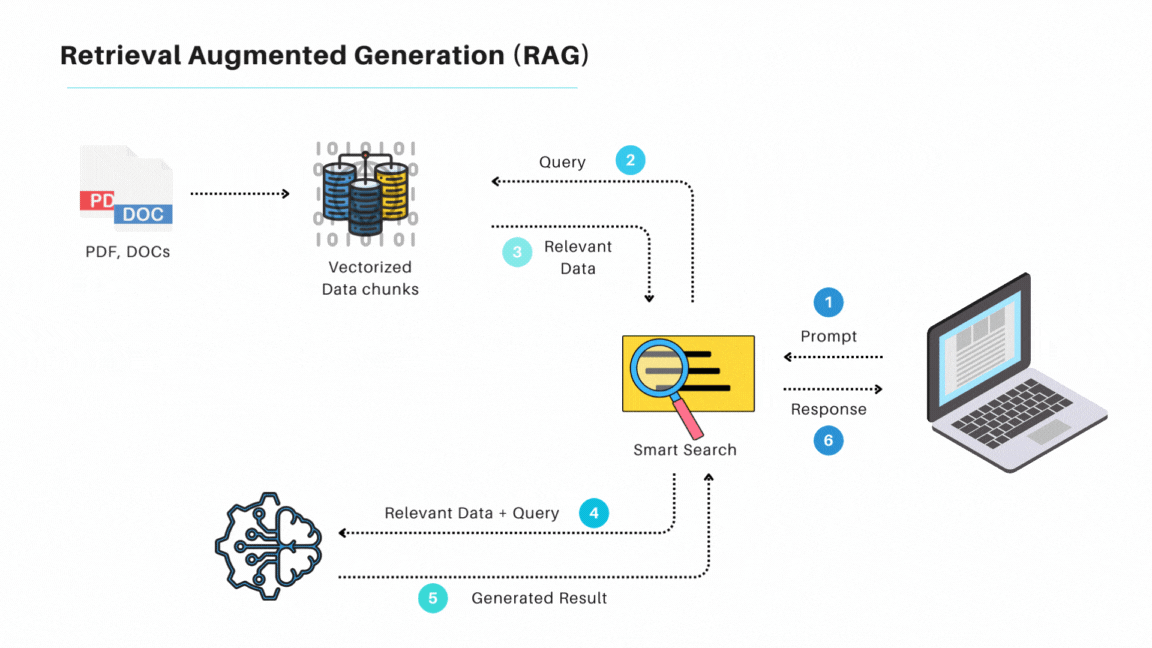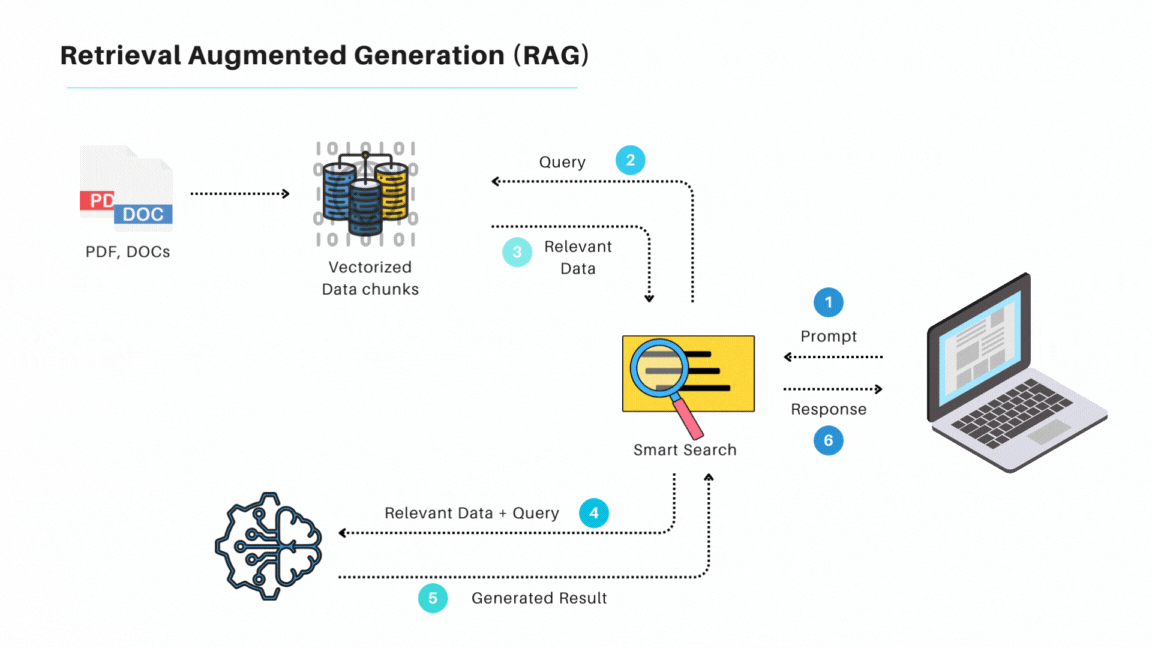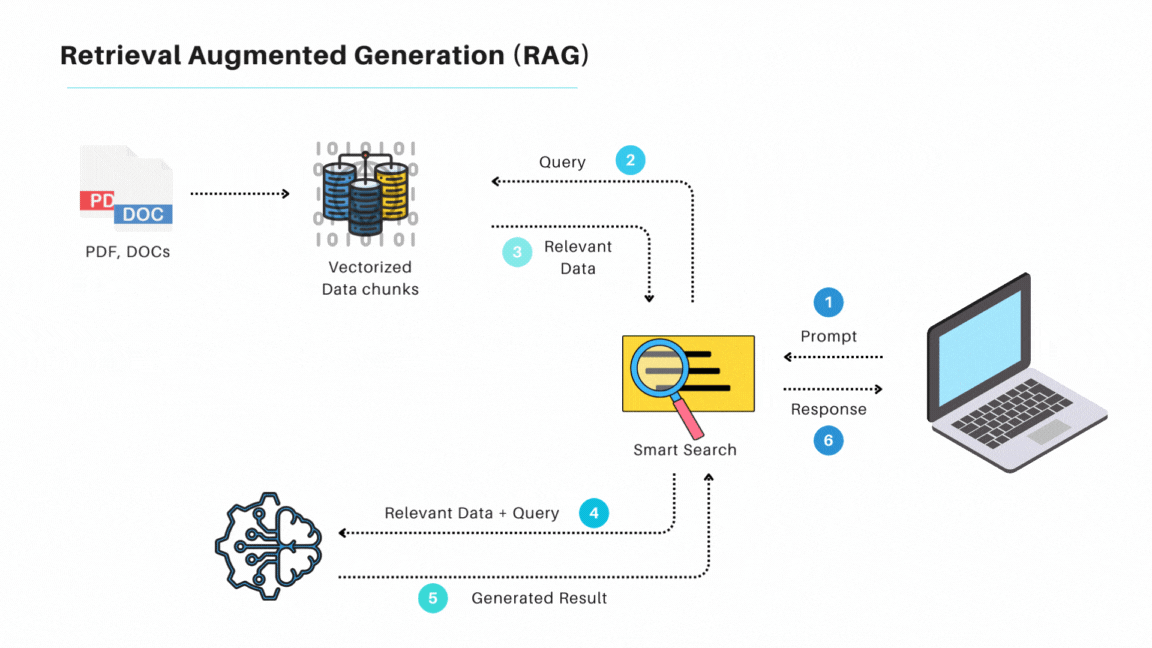
본격적인 설명에 앞서 기존 RAG 방법에 대해 짧게 리마인드 해봅시다.
RAG(Retrieval-Augmented Generation)는 외부 데이터베이스나 문서를 참조해서, LLM의 학습 데이터에 포함되지 않은 최신의 도메인 특화 정보를 LLM이 답변할 수 있도록 해주었습니다.
이런 장점으로인해 지금까지 QA시스템, 챗봇 등의 NLP task에서 널리 사용되고 있죠.
RAG는 이처럼 문서의 특정 부분을 참조해 답을 찾는 것에 효과적이지만 다음과 같은 한계점도 존재하는데요.
한계1. 글로벌 질문 처리의 어려움
“이 데이터셋 전체의 주요한 주제는 무엇인가?(What are the main themes in the dataset?)”와 같이 전체 문서의 corpus에 대한 글로벌 질문에 답하는 것에는 어려워합니다.
한계2. 정보의 지역성
전체 문서 컬렉션에 걸쳐 분산된 정보를 종합하는 데 제한적입니다.
한계3. 컨텍스트 윈도우 크기의 제한
LLM 컨텍스트 윈도우 크기 제한으로 대규모 문서 컬렉션 전체를 한 번에 처리하기 어렵습니다.
한계4. 복잡한 추론의 어려움
단순 정보 검색을 넘어서는 복잡한 추론이 필요한 질문에 대해서는 성능이 제한적입니다.
전체 텍스트나 말뭉치를 대상으로 하는 전역적 질문을 처리하는 작업을 쿼리 중심 요약(Query Focused Summary,QFS)이라고 합니다.
QFS는 주어진쿼리에 초점을 맞춰 관련 정보만을 추출하고 요약하기 때문에, 쿼리에 대해서 직접적인 답변을 제공합니다.
연구팀은 RAG의 글로벌 질문에 대한 약점을 QFS 방법론을 통해 개선하고자 했습니다.
그러나 기존 QFS는 전체 문서 집합을 대상으로 쿼리와 관련된 정보를 추출하기 때문에, 문서의 양이 증가할수록 계산량이 급격하게 증가한다는 단점이 존재했습니다.
연구팀은 이를 해결하고자 LLM을 활용해 커뮤니티 그룹 단위의 요약을 생성하고, 이를 그래프 구조로 조직화해 QFS의 확장성 문제를 해결하고자 했습니다.
지금까지 GraphRAG의 등장 배경에 간단하게 살펴보았습니다. 다음은, GraphRAG의 접근과 데이터 구축 단계에 대해서 알아보겠습니다.
GraphRAG Approach & Pipeline
GraphRAG 방법론은 크게 두 단계로 그래프 기반 인덱스를 구축합니다.
- 소스 문서에서 엔티티 지식 그래프 도출
- 밀접하게 관련된 모든 엔티티 그룹에 대한 커뮤니티 요약 사전 생성
먼저 소스 문서에서 엔티티 지식 그래프를 도출하는 파이프라인에 대해 설명하겠습니다.
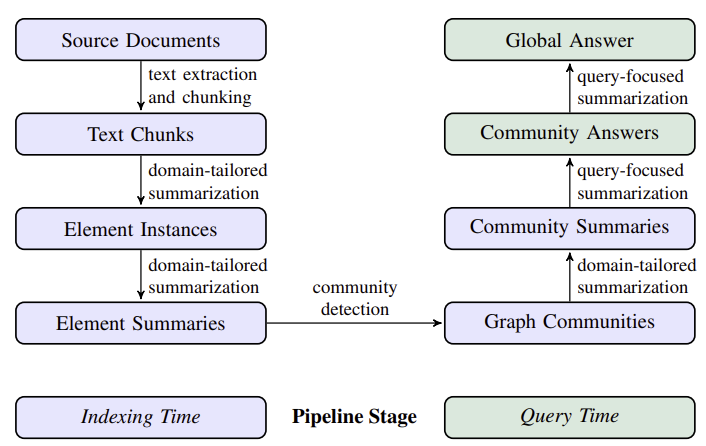
1. Source Document -> Text Chunks
문서를 엔티티 추출을 위해 청킹하는 단계입니다.
- 어떤 크기의 chunk로 나눌 것인가?
- 더 긴 chunk는 LLM의 호출 횟수를 줄이지만, 긴 컨텍스트 윈도우에서 발생하는 Recall 저하 문제가 발생합니다.
- HotPotQA에서 600토큰 크기 청크 사용 시 2400 토큰 크기 사용했을 때보다 거의 두 배 많은 엔티티 참조를 추출합니다.
- 추출 프로세스는 목표 활동에 대한 Recall과 Precision의 균형을 맞춰야합니다.
2. Text Chunks → Element Instances
앞서 청킹한 텍스트에서 그래프 노드와 엣지의 인스턴스를 식별하고 추출하는 단계입니다.
쉽게 설명하면 각 엔티티들을 노드로 취급하고, 엔티티간의 관계를 명시적으로 표현함으로써 그래프처럼 엔티티가 연결되도록 한 것입니다.
- multipart LLM prompt를 사용해 모든 엔티티(이름, 유형, 설명 포함)를 식별하고, 관련된 엔티티간의 모든 관계를 식별합니다.
1
2
3
4
5
6
7
8
9
10
# 의학 도메인, multipart LLM prompt 예시
"""
[Part 1: 엔티티 식별]
다음 의료 텍스트에서 환자, 증상, 질병, 약물, 치료법, 의료진을 식별하세요. 각 엔티티에 대해 고유 ID, 이름, 유형, 간단한 설명을 제공하세요.
[Part 2: 관계 식별]
Part 1에서 식별한 엔티티들 사이의 관계를 파악하세요. 각 관계에 대해 고유 ID, 소스 엔티티 ID, 대상 엔티티 ID, 관계 유형, 관계 설명을 제공하세요.
입력 텍스트:
"45세 여성 환자가 2주 동안 지속된 두통과 현기증을 호소하며 내원했습니다. 혈압 검사 결과 160/100mmHg로 고혈압 진단을 받았습니다. 의사는 생활습관 개선과 함께 ACE 억제제인 리시노프릴을 처방했습니다."
- 필요에 따라 특정 도메인에 맞춰 프롬프트를 조정할 수 있는데, 주로 few-shot 학습을 위한 예제 선택을 통해 이뤄집니다.
1
2
3
4
5
6
7
8
9
10
11
12
# 법률 도메인:
프롬프트: """
다음 법률 문서에서 법적 개념, 판례, 법령, 당사자를 식별하세요.
Few-shot 예제:
입력: "Brown v. Board of Education 사건에서 대법원은 '분리하되 평등' 원칙이 위헌이라고 판결했습니다."
출력:
판례: Brown v. Board of Education
법적 개념: '분리하되 평등' 원칙
당사자: 대법원
"""
- 기타 공변량을 추출하기 위한 보조 추출 프롬프트를 지원합니다.
- “gleaning” 다중 라운드 추출 방식 사용해 이전 라운드에 놓쳤을 수 있는 추가 엔티티 감지
- 품질 저하, 노이즈 없이 더 큰 청크 크기 사용 가능
예시를 통해 알아보면
텍스트 “Microsoft와 GitHub는 협력하여 오픈 소스 프로젝트를 지원하고 있습니다. Satya Nadella는 Microsoft의 CEO이며, GitHub의 CEO는 Thomas Dohmke입니다.”가 주어졌을 때,
이 텍스트를 기반으로 엔티티와 관계를 추출하면
엔티티
- Microsoft
- GitHub
- Satya Nadella
- Thomas Dohmke
관계
- Microsoft, GitHub: 협력
- Satya Nadella, Microsoft: CEO
- Thomas Dohmke, GitHub: CEO
지식그래프
Microsoft – 협력 –> GitHub
Microsoft – CEO –> Satya Nadella
GitHub – CEO –> Thomas Dohmke
3. Element Instances → Element Summaries
앞서 추출된 요소 인스턴스들을 요약하는 과정입니다.
추출된 엔티티와 관계를 기반으로 각 문장의 요약을 생성하고, 요약은 지식 그래프의 요소로 사용됩니다.
이 단계에서 LLM이 동일한 엔티티를 일관되지 않은 방식으로 요약을 생성할 수 있는데,
이후 단계에서 엔티티들의 “커뮤니티”를 감지하고 요약을 하기 떄문에 탄력적으로 접근할 수 있다고 논문은 말합니다.
앞선 예시에 이어서 설명하자면,
- “Microsoft와 GitHub는 협력 관계에 있다.”
- “Satya Nadella는 Microsoft의 CEO이다.”
- “Thomas Dohmke는 GitHub의 CEO이다.”
이런식으로 엔티티와 관계를 기반으로 요약을 만든다고 이해하시면 됩니다.
그림의 가운데 부분 진행중
4. Element Summaries → Graph Communities
생성된 요약들을 그래프 커뮤니티로 구성하는 과정입니다.
여기서 커뮤니티란, 그래프의 다른 노드들보다 서로 더 강한 연결을 가진 노드들의 그룹을 의미합니다.
그래프의 특징은 다음과 같습니다.
- 그래프 모델링
- 동종(Homogeneous) 그래프: 모든 노드가 같은 유형이다. 사람, 장소, 개념 등 모든 엔티티가 ‘노드’로 취급
- 무방향(Undirected) 그래프: Edge에 방향성이 없다. A→B의 관계는 B←A 관계와 동일하다.
- 가중(Weighted) 그래프: 각 Edge에 가중치를 부여한다. 가중치는 감지된 관계 인스턴스의 정규화된 수를 나타낸다. 두 엔티티 관계가 텍스트에서 자주 언급될수록 해당 엣지의 가중치가 높아진다.
- 커뮤니티 탐지
- 다양한 커뮤니티 탐지 알고리즘을 사용해 그래프를 파티셔닝할 수 있다.
- Liden 알고리즘 사용
- Liden 알고리즘은 대규모 그래프의 계층적 커뮤니티 구조를 효율적으로 복구할 수 있다.
- 계층적 구조
- 이 알고리즘은 그래프의 계층적 커뮤니티 구조를 생성한다.
- 각 계층 레벨은 그래프의 노드를 상호 배타적이고 집합적으로 완전한 방식으로 커버하는 커뮤니티 파티션을 제공한다.
- 분할 정복 접근
- 분할 정복 방식의 커뮤니티별 요약을 가능하게 한다. (최하위 레벨 커뮤니티 요약 -> 중간 레벨 커뮤니티 요약 -> 최상위 레벨 커뮤니티 요약)
- 시각화
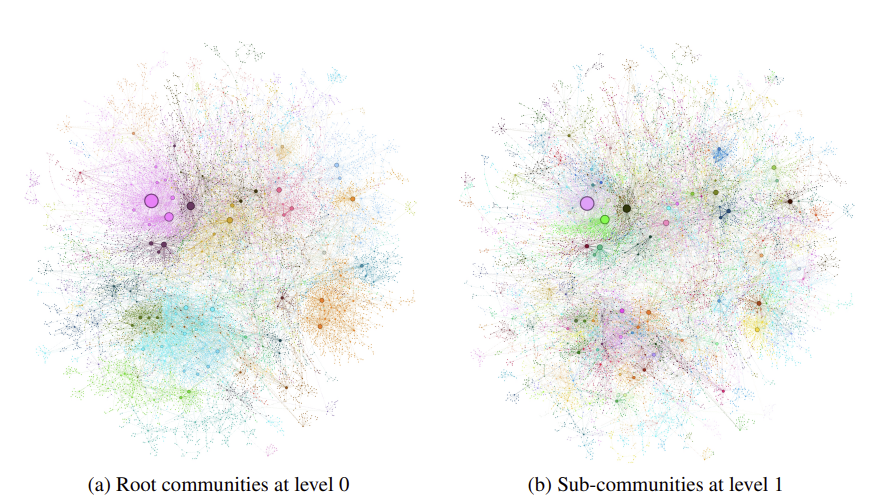
왼쪽은 level-0인 뿌리 커뮤니티의 군집을 확인할 수 있고,
오른쪽은 level-1은 하위 커뮤니티들을 확인할 수 있습니다.
5. Graph Communities → Community Summaries
이 단계는 Leiden 알고리즘을 활용해 생성된 그래프 커뮤니티를 요약하는 과정입니다.
요약 생성 방법
- 리프 레벨 커뮤니티
- 커뮤니티의 요소(노드, 엣지, 공변량)를 순위화
- LLM 컨텍스트 제한이 도달할때까지 반복적으로 요소 추가
- 각 엣지에 대해 엣지의 소스 노드에 대한 설명 + 대상 노드의 설명 + 해당 엣지와 연관된 공변량(추가 속성) + 엣지 자체의 설명(관계 설명)
- 상위 레벨 커뮤니티
- 리프 레벨과 같은 방식으로 진행
- 커뮤니티 내의 모든 요소 요약(노드, 엣지, 공변량에 대한 설명)이 LLM의 컨텍스트 윈도우에 맞는지 확인
- 하위 커뮤니티들을 요약의 길이(토큰 수)에 따라 내림차순으로 정렬
- 가장 긴 요약부터 시작하여, 원래의 긴 요소 요약 대신 이미 만들어진 짧은 하위 커뮤니티 요약으로 대체
- 컨텍스트 윈도우에 맞을 때까지 진행
- 중요한 정보는 유지하면서도 전체 크기를 줄인다.
앞선 예시에 이어서 다시 커뮤니티에 대해 설명하자면,
Microsoft를 중심으로 한 커뮤니티를 가정할 때, 커뮤니티 요약은 다음과 같이 생성됩니다.
리프 노드 요약
Satya Nadella는 Microsoft의 CEO이다.
로컬 커뮤니티 요약
Microsoft는 GitHub와 협력 관계에 있으며, Satya Nadella가 CEO이다
상위 레벨 커뮤니티 요약
“Microsoft”와 “LinkedIn” 커뮤니티를 대상으로,
Microsoft는 GitHub와 협력 관계에 있으며, Satya Nadella가 CEO이다. 또한, Microsoft는 LinkedIn을 인수하였으며, LinkedIn의 CEO는 Ryan Roslansky이다”
이 과정은 복잡한 정보 구조를 단계적으로 요약해 이해하기 쉽도록 만들어줍니다.
요약된 커뮤니티는 다음 단계에서 사용자 쿼리에 대한 답변을 생성하는데 사용됩니다.
6. Community Summaries → Community Answers → Global Answer
사용자 쿼리에 대한 답변을 생성하는 단계입니다.
커뮤니티 요약을 활용하고, 계층적 구조를 활용해 다양한 레벨의 요약을 사용할 수 있다고합니다.
글로벌 답변 생성 과정
- 커뮤니티 요약 준비
- 커뮤니티 요약을 무작위로 섞는다.
- 섞인 요약들을 미리 지정된 토큰 크기의 청크로 나눈다.
- 정보가 청크 전체에 분산되는 효과
- 커뮤니티 답변 매핑
- 각 청크에 대해 병렬로 중간 답변을 생성
- LLM에세 각 답변을 0-100 사이 점수로 평가 요청
- 점수가 0인 답변 필터링해서 제거
- 글로벌 답변으로 축소
- 점수의 내림차순으로 정렬
- 정렬된 답변을 컨텍스트 윈도우에 반복적으로 추가
- 최종 컨텍스틀 사용해 사용자에게 반환할 글로벌 답변 생성
평가
1. 데이터셋
Podcast transcripts, News articles이라는 100만 토큰 범위의 데이터셋을 사용했습니다.
Podcast transcripts
- Microsoft CTO와 다른 기술 리더들 간의 대화 트랜스크립트 모음
- 1,669개의 600토큰 텍스트 청크 (청크 간 100토큰 중복)
- 총 크기: 약 100만 토큰
News articles
- 2013년 9월부터 2023년 12월까지 발행된 뉴스 기사
- 3,197개의 600토큰 텍스트 청크 (청크 간 100토큰 중복)
- 총 크기: 약 170만 토큰
이 데이터들은 방대한 양의 텍스트와 대화/다양한 주제의 기사라는 다양성을 가지며, 실제성과 시의성을 고려해 채택되었습니다.
2. Query
저자들은 기존의 오픈 도메인 질문 답변 데이터셋이 명시적인 사실 검색에 초점을 맞추고 있어서, 데이터 센스메이킹을 위한 요약 목적에는 적합하지 않다고 판단했습니다.
데이터셋에 대한 간단한 설명을 바탕으로 LLM에세 잠재적인 사용자와 태스크를 식별해 각 (사용자, 태스크) 조합에 대해 N개의 질문을 생성했습니다.
생성된 쿼리들은 데이터셋 내용에 대한 높은 수준의 이해만을 반영하고, 글로벌 센스메이킹 태스크에 적합한 질문들로 구성되었습니다.
3. 실험 조건
6가지 조건을 선정하고 비교했습니다.
- Graph RAG의 4가지 레벨의 그래프 커뮤니티 (C0, C1, C2, C3), 숫자가 높아질수록 루트에 가깝습니다.
- 텍스트 요약 방법 (TS,Text Summarization), 커뮤니티 요약 대신 원본 텍스트를 직접 요약
- 단순 “의미론적 검색” RAG 접근법 (SS, Semantic Search, 나이브 RAG), 전통적인 RAG 접근법
모든 조건에서 동일한 크기의 컨텍스트 윈도우와 유사한 답변 프롬프트를 사용했고, 데이터셋 도메인에 맞춰 엔티티 유형과 few-shot 예제를 조정했다고 합니다.
4. 평가 지표:
- LLM을 평가자로 사용하여 head-to-head 비교 수행
- 주요 지표: 포괄성, 다양성, 권한 부여, 직접성
포괄성 (Comprehensiveness): 답변이 질문의 모든 측면과 세부사항을 얼마나 자세히 다루는지
다양성 (Diversity): 답변이 얼마나 다양하고 풍부한 관점과 통찰을 제공하는지
권한 부여 (Empowerment): 답변이 독자가 주제를 이해하고 정보에 기반한 판단을 내리는 데 얼마나 도움이 되는지
직접성 (Directness): 답변이 얼마나 구체적이고 명확하게 질문을 다루는지 (대조군으로 사용) - 각 비교를 5번 반복하여 평균 점수 사용
5. 구성:
- 다양한 컨텍스트 윈도우 크기 (8k, 16k, 32k, 64k) 테스트
- 8k 토큰 크기가 가장 좋은 성능을 보여 최종 평가에 사용
6. 결과

그래프 구조에서 팟캐스트 데이터셋은 8564개의 노드와 20691개의 엣지, 뉴스 데이터셋은 15754개의 노드와 19520개의 엣지를 생성했습니다.
전역 접근법 vs 나이브한 RAG
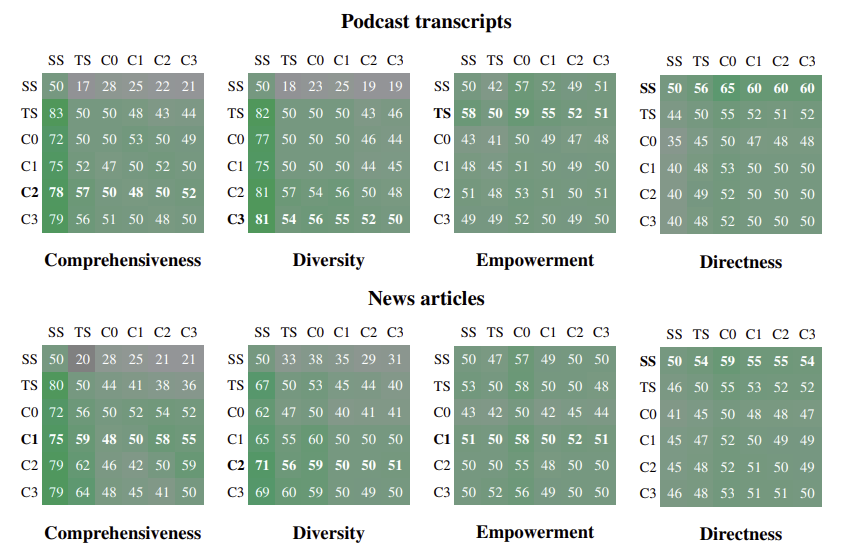
모든 전역 접근법(Graph RAG와 TS)이 나이브 RAG보다 포괄성과 다양성 측면에서 우수했습니다.
팟캐스트 데이터셋에서 포괄성 72~83%, 다양성 75~85승률
뉴스 데이터셋에서 포괄성 72~80%, 다양성 62~71% 승률을 보였습니다.
커뮤니티 요약 vs 소스 텍스트 요약
Graph RAG의 중간 및 하위 레벨 커뮤니티 요약(C2, C3)이 소스 텍스트 요약(TS)보다 약간 더 나은 성능
팟캐스트 데이터셋에서 C2에서 포괄성 57% 승률, 다양성 57% 승률
뉴스 데이터셋에서 C3에서 포괄성 64% 승률, 다양성 60% 승률을 보였습니다.
효율성
Graph RAG(C3)는 TS보다 26-33% 적은 컨텍스트 토큰을 사용했고
루트 레벨 Graph RAG(C0)는 TS보다 97% 이상 적은 토큰으로 경쟁력 있는 성능을 달성했습니다.
C0는 나이브 RAG 대비 포괄성 72% 승률, 다양성 62% 승률을 달성했습니다.
권한 부여 (Empowerment):
혼합된 결과를 보였으며 특정 예시, 인용, 출처 제공 능력이 중요한 요소로 작용했다고합니다.
궁금한 점이 실험 조건을 왜 커뮤니티 레벨 별로 나누어 비교했는가 였는데,
각 레벨은 서로 다른 상세도와 범위를 가지기 때문에, 이렇게 나눠서 비교를 함으로써 계층적 구조의 영향 평가가 가능하다고 합니다. 어떤 레벨의 커뮤니티 구조가 가장 효과적인지 파악이 가능하겠죠.
적응성과 유연성 측면에서 전체적인 주제에 대한 질문은 상위 레벨에서, 세부적인 질문은 하위 레벨에서 더 잘 다룰수 있어 실제 시스템에서 사용자의 다양한 요구에 맞춰 유연하게 조정이 가능하다는 가능성도 시사합니다.
결론
결론에서 연구진들은 GraphRAG라는 새로운 접근법에서 지식 그래프 생성, 검색 증강 생성(RAG), 그리고 쿼리 중심 요약(QFS)을 결합하여 대규모 텍스트 데이터에 대한 인간의 이해를 돕는다고 설명합니다.
주요 특징과 결과로 강조하는 부분은 다음과 같습니다.
- 이 데이터셋의 주요 주제는 무엇인가요?”와 같은 전역적 질문에 뛰어난 성능
- 기존의 나이브 RAG 방식과 비교해 답변의 포괄성과 다양성이 크게 개선
- 특히 루트 레벨 커뮤니티 요약을 사용할 때, 다른 전역적 방법들과 비슷한 성능을 훨씬 적은 컴퓨팅 자원으로 달성
- 다양한 레벨의 커뮤니티 구조를 활용해 다양한 유형의 질문에 적응
- 대규모 데이터셋에서도 효과적으로 작동, 사용자 질문의 일반성과 소스 텍스트의 양에 따라 확장 가능
연구진은 이 결과가 대규모 텍스트 데이터를 다루는 방식에 새로운 지평을 열었으며, Graph RAG는 단순히 정보를 검색하는 것을 넘어, 데이터의 전체적인 구조와 의미를 파악하는 데 도움을 준다고 합니다.
추후 연구로 다양한 도메인과 더 큰 규모의 데이터셋에 대한 Graph RAG의 성능을 탐구할 예정이며, 사용자 피드백을 통해 시스템을 더욱 개선하고 실제 응용 사례를 개발할 계획이라고 합니다.
아래는 마이크로소프트가 이 방법론에 대해 정리한 블로그를 첨부했습니다.
나이브한 RAG 방법론과의 비교가 잘 드러남으로 참고하면 재미있을 것 같습니다.
블로그: GraphRAG: Unlocking LLM discovery on narrative private data