데이터 엔지니어링, 파이프라인과 저장소
데이터 엔지니어링?
대규모 데이터를 효율적으로 수집, 저장, 처리, 분석할 수 있도록 하는 일련의 프로세스와 기술을 의미한다.
JD 예시 
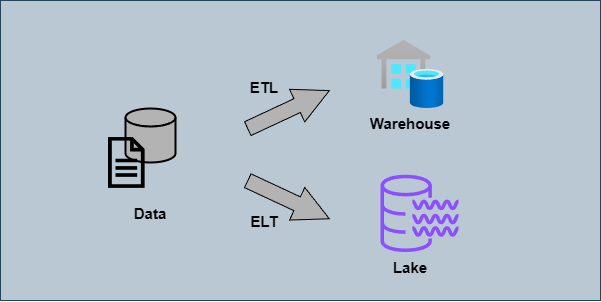
ETL, ELT?
데이터를 처리하는 두 가지 접근 방식
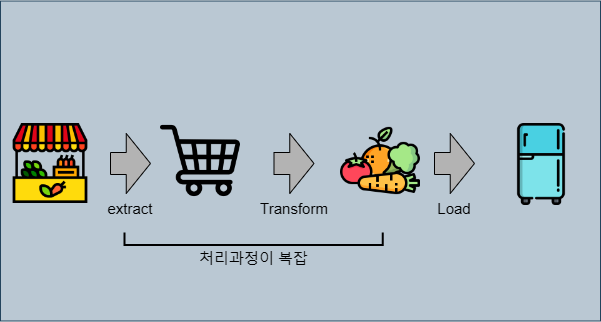
ETL (Extract, Transform, Load):
- 데이터를 소스에서 추출하고, 중간 단계에서 변환한 후, 최종 목적지에 적재
- 마치 요리사가 재료를 가져와(Extract), 주방에서 손질하고 조리한 후(Transform), 손질된 상태로 냉장고에 넣어두는(Load) 것과 유사
- 미리 재료를 손질해두어, 나중에 빠르게 요리할 수 있도록 준비
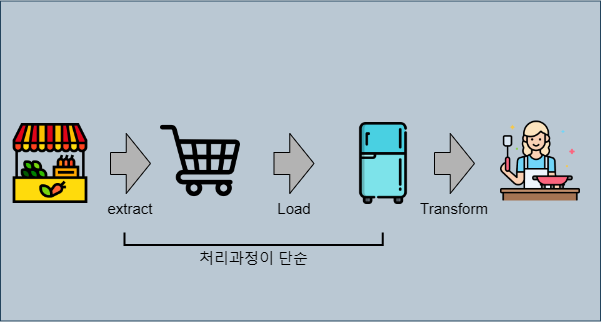
ELT (Extract, Load, Transform):
- 데이터를 소스에서 추출하여 바로 목적지에 적재한 후, 그 자리에서 변환 작업을 수행
- 마치 요리사가 모든 식재료를 식당으로 가져와(Extract) 냉장고에 넣어두고(Load), 주문이 들어올 때마다 필요한 요리로 변환(Transform)하는 것
- 요리할 때 꺼내서 그때그때 필요한 대로 손질하고 요리
주요 차이점:
- ETL은 데이터를 적재하기 전에 정제하므로 저장 공간을 절약할 수 있지만, 처리 과정이 더 복잡(더 많은 스토리지 요구)
- ELT는 모든 원본 데이터를 저장하므로 더 많은 저장 공간이 필요하지만, 필요에 따라 유연하게 데이터를 변환 가능
최근 클라우드 스토리지의 발전으로 대용량 데이터 저장이 저렴해지고, 원본 데이터 보존시 데이터 활용이 유연해지는 등의 장점 때문에 ETL을 널리 사용하고 있다.
이제 ETL의 각 과정에 대해 알아보자
Extract
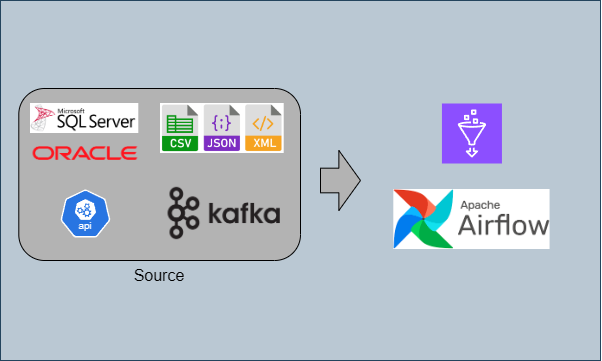
정의: 다양한 소스 시스템에서 데이터를 추출하여 처리 가능한 형태로 가져오는 과정
- 소스:
- 관계형 데이터베이스 (예: Oracle, SQL Server)
- 파일 시스템 (예: CSV, JSON, XML 파일)
- API (예: REST API, SOAP 웹서비스)
- 스트리밍 데이터 (예: Kafka, Apache Flink)
- 웹 스크래핑 (예: 웹사이트 데이터)
- 방식:
- 전체 추출: 소스의 모든 데이터를 추출
- 증분 추출: 마지막 추출 이후 변경된 데이터만 추출
- 로그 기반 추출: 데이터베이스 로그를 이용한 변경 데이터 캡처
- 도구:
- Apache Airflow: 워크플로우 관리 및 스케줄링 플랫폼
- Apache Spark: 대규모 데이터 처리를 위한 분산 컴퓨팅 프레임워크
- AWS Glue: 서버리스 데이터 통합 서비스
- 고려사항:
- 데이터 볼륨과 추출 빈도
- 소스 시스템에 대한 부하 최소화
- 데이터 일관성 및 무결성 유지
Transform
정의: 추출 혹은 로드된 데이터를 목적에 맞게 변환, 정제, 통합하는 과정
- 주요 작업:
- 데이터 정제: 오류 수정, 중복 제거
- 데이터 표준화: 형식 통일, 코드 매핑
- 데이터 집계: 요약 통계 생성
- 데이터 병합: 여러 소스의 데이터 통합
- 방식:
- 배치 처리: 주기적으로 대량의 데이터 변환
- 스트림 처리: 실시간으로 데이터 변환
- 인메모리 처리: 메모리 내에서 빠른 데이터 변환
- 도구:
- Apache Spark: 대규모 데이터 처리를 위한 분산 컴퓨팅 프레임워크
- Apache Airflow: 워크플로우 관리 및 스케줄링 플랫폼
- AWS Glue: 서버리스 데이터 통합 서비스
- 고려사항:
- 데이터 품질 보장
- 변환 규칙의 유지보수 용이성
- 성능 최적화
- 데이터 계보(lineage) 추적
※데이터 계보: 시간 경과에 따른 데이터 흐름을 추적하는 프로세스로, 데이터의 출처, 데이터에 일어난 변화, 데이터 파이프라인 내에서의 최종 목적지에 대한 자세한 정보를 제공
Load
정의: 데이터를 목적지 시스템(대개 데이터베이스, 데이터 웨어하우스, 데이터 레이크 등)에 삽입하거나 업데이트하는 과정
- 대상:
- 관계형 데이터베이스 (예: MySQL, PostgreSQL)
- 데이터 웨어하우스 (예: Amazon Redshift, Google BigQuery, Snowflake)
- 데이터 레이크 (예: AWS S3, Azure Data Lake Storage)
- NoSQL 데이터베이스 (예: MongoDB, Cassandra)
- 방식:
- 벌크 로드: 대량의 데이터를 한 번에 적재
- 증분 로드: 새로운 또는 변경된 데이터만 적재
- 실시간 로드: 데이터가 생성되는 즉시 지속적으로 적재
- 도구:
- Apache Spark: 대규모 데이터 처리를 위한 분산 컴퓨팅 프레임워크
- Apache Airflow: 워크플로우 관리 및 스케줄링 플랫폼
- AWS Glue: 서버리스 데이터 통합 서비스
- 데이터 통합 플랫폼 (예: Airbyte, Fivetran)
- 사용자 역할 :
- 데이터 사용자는 로드된 데이터를 쿼리, 분석, 시각화하는 등의 작업을 수행
BI TOOL 활용(선택)
- 데이터 시각화
- 차트, 그래프, 대시보드 생성
- 예: 매출 추이 라인 차트, 지역별 판매량 맵 차트
- 인사이트 도출
- 데이터 패턴 및 트렌드 분석
- 예: 최고 매출 제품 식별, 성과가 저조한 지역 파악
- 리포트 생성
- 정기적인 비즈니스 리포트 자동화
- 예: 월간 판매 보고서, 분기별 성과 요약
데이터 웨어하우스? 레이크?
데이터 웨어하우스
정의: 구조화된 데이터를 저장하고 분석하기 위한 중앙 저장소
- 특징:
- 구조화된 데이터 저장 (예: SQL 테이블)
- 스키마 온 라이트 (저장 시 스키마 정의)
- 주로 비즈니스 인텔리전스(bi)에 사용
- 장점:
- 빠른 쿼리 성능
- 일관된 데이터 구조
- 단점:
- 변경에 덜 유연함
- 대용량 비정형 데이터 처리에 부적합
- Amazon Redshift
- AWS의 페타바이트 규모 데이터 웨어하우스 서비스
- 높은 확장성과 빠른 쿼리 성능
- Google BigQuery
- 서버리스 데이터 웨어하우스
- 대규모 데이터 분석에 적합
- 사용 예: 재무 보고, 판매 분석
데이터 레이크
- 정의: 모든 종류의 데이터를 원시 형태로 저장하는 대규모 저장소
- 특징:
- 구조화, 반구조화, 비구조화 데이터 모두 저장
- 스키마 온 리드 (읽을 때 스키마 정의)
- 빅데이터 분석, 머신러닝에 적합
- 장점:
- 높은 유연성
- 모든 종류의 데이터 저장 가능
- 단점:
- 데이터 품질 관리가 어려울 수 있음
- 초기 쿼리 성능이 상대적으로 낮을 수 있음
사용 예: 로그 분석, 고객 행동 패턴 분석
- Apache Hadoop
- 분산 데이터 처리 프레임워크
- HDFS를 통한 대용량 데이터 저장
- Apache Spark
- 인메모리 데이터 처리
- 배치 및 스트리밍 처리 지원
정리
두 저장 공간에 대한 예를 들면,
- 데이터 웨어하우스: 정돈된 도서관
- 책(데이터)이 주제별로 잘 정리되어 있음
- 원하는 정보를 빠르게 찾을 수 있음
- 새로운 형태의 자료 추가가 어려울 수 있음
- 데이터 레이크: 거대한 창고
- 모든 종류의 물건(데이터)을 그대로 보관
- 다양한 용도로 활용 가능
- 원하는 물건을 찾는 데 시간이 걸릴 수 있음
비교
| 특성 | 데이터 웨어하우스 | 데이터 레이크 |
|---|---|---|
| 데이터 구조 | 구조화된 데이터 | 구조화, 반구조화, 비구조화 데이터 |
| 스키마 | 스키마 온 라이트 (저장 시 정의) | 스키마 온 리드 (읽을 때 정의) |
| 데이터 품질 | 처리된, 정제된 데이터 | 원시 데이터 |
| 사용자 | 비즈니스 분석가, 데이터 분석가 | 데이터 과학자, 데이터 분석가 |
| 접근성 | 쉬운 접근 및 쿼리 | 더 복잡한 접근 (ETL/데이터 준비 필요) |
| 성능 | 빠른 쿼리 성능 | 대용량 처리에 최적화 |
| 확장성 | 제한적 | 높음 |
| 비용 | 초기 비용 높음, 저장 비용 높음 | 초기 비용 낮음, 저장 비용 낮음 |
| 유연성 | 낮음 (변경에 시간 소요) | 높음 (새로운 데이터 유형 쉽게 추가) |
| 보안 | 강력한 보안 및 액세스 제어 | 보안 구현이 더 복잡할 수 있음 |
| 주요 용도 | 보고, BI, 대시보드 | 빅데이터 분석, 머신러닝, 데이터 탐색 |
| 데이터 변경 | 자주 갱신됨 | 보통 한 번 쓰고 자주 읽음 |
| 역사성 | 수십 년된 성숙한 기술 | 비교적 새로운 기술 |
| 비유 | 정돈된 도서관 | 대형 창고 |
파이프라인과 저장공간의 상관관계와 최근 트랜드
지금까지의 내용을 살펴보면 데이터 파이프라인과 저장 방법 간의 한가지 유사성을 확인할 수 있는데,
ETL + 데이터 웨어하우스 : 정형화된 데이터 처리에 최적화되었고, 데이터를 저장 전에 변환한다. (early-binding)
ELT + 데이터 레이크 : 다양한 형태의 대규모 데이터 처리에 적합하고 데이터를 사용 시점에서 변환한다. (late-binding)
최근에는 실시간 처리의 중요성이 증가하면서 데이터 레이크와 웨어하우스의 장점을 결합한 하이브리드 방법을 사용 한다.
- 데이터 레이크하우스 (Databricks Delta Lake, Snowflake) : 원시 데이터와 처리 데이터 모두 저장
- 클라우드 네이티브 솔루션 (AWS Redshift Spectrum, Google BigQuery)
챗봇을 위한 데이터 파이프라인(ELT) 예시
Extract 예시
- 고객 상담 채팅 로그 추출:
- 네이버 톡톡, 카카오톡 채널 API를 사용하여 상담 내역 추출
- 대화 내용, 시간, 고객 ID, 상담사 ID 등 메타데이터 포함
- SNS 데이터 수집:
- 네이버 블로그, 인스타그램 API를 통해 브랜드 관련 포스트, 댓글 추출
- 텍스트 내용, 작성자 정보, 게시 시간, 해시태그 등 수집
- 내부 지식베이스 데이터 추출:
- 회사 내부 위키, 상품 설명서, 자주 묻는 질문 등을 데이터베이스에서 추출
- 문서 제목, 내용, 카테고리, 최종 수정일 등의 정보 포함
- 웹사이트 크롤링:
- 회사 공식 홈페이지, 네이버 지식iN 등에서 관련 정보 크롤링
- HTML 파싱을 통해 필요한 한국어 텍스트 정보 추출
- 음성 데이터 추출:
- KT, SK 등 통신사 콜센터 녹음 파일에서 한국어 음성 데이터 추출
- 한국어 음성인식(STT) 통해 텍스트로 변환하여 저장
Load 예시
- 관계형 데이터베이스 적재:
- MySQL이나 PostgreSQL에 고객 상담 데이터 적재
- 예:
INSERT INTO customer_inquiries (customer_id, inquiry_text, timestamp) VALUES (?, ?, ?)
- 데이터 웨어하우스 적재:
- Amazon Redshift나 Google BigQuery에 대량의 SNS 데이터 적재
- 예:
COPY sns_posts FROM 's3://bucket-name/sns-data/' CREDENTIALS 'aws_access_key_id=...;aws_secret_access_key=...'
- 데이터 레이크 적재:
- AWS S3나 Azure Data Lake Storage에 원시 데이터 파일 저장
- 예:
aws s3 sync /local/raw-data s3://my-data-lake/raw/
- 그래프 데이터베이스 적재:
- Neo4j에 고객 관계 데이터 저장
- 예:
CREATE (c:Customer {id: '1001', name: '김철수'})-[:PURCHASED]->(p:Product {id: 'A101', name: '스마트폰'})
Transform 예시
- 텍스트 정제 (Text Cleaning)
- 목적: 노이즈 제거 및 텍스트 표준화
- 작업:
- 특수 문자 제거
- 대소문자 통일
- 불필요한 공백 제거
- 예시 코드 (Python):
1 2 3 4 5 6 7 8 9 10
import re def clean_text(text): text = re.sub(r'[^\w\s]', '', text) # 특수 문자 제거 text = text.lower() # 소문자 변환 text = re.sub(r'\s+', ' ', text).strip() # 과도한 공백 제거 return text cleaned_text = clean_text("Hello, World! How are you?") # 결과: "hello world how are you"
- 토큰화 (Tokenization)
- 목적: 텍스트를 개별 단위(토큰)로 분리
- 작업:
- 문장을 단어 또는 서브워드 단위로 분리
- 예시 코드 (NLTK 사용):
1 2 3 4 5 6 7
from nltk.tokenize import word_tokenize def tokenize_text(text): return word_tokenize(text) tokens = tokenize_text("Hello, how are you?") # 결과: ['Hello', ',', 'how', 'are', 'you', '?']
- 불용어 제거 (Stop Words Removal)
- 목적: 의미 없는 일반적인 단어 제거
- 작업:
- 미리 정의된 불용어 목록을 사용하여 필터링
- 예시 코드 (NLTK 사용):
1 2 3 4 5 6 7 8 9
from nltk.corpus import stopwords stop_words = set(stopwords.words('english')) def remove_stopwords(tokens): return [word for word in tokens if word.lower() not in stop_words] filtered_tokens = remove_stopwords(['Hello', 'how', 'are', 'you']) # 결과: ['Hello']
- 어근 추출 (Lemmatization)
- 목적: 단어를 기본 형태(레마)로 변환
- 작업:
- 단어의 어근 추출
- 예시 코드 (spaCy 사용):
1 2 3 4 5 6 7 8 9 10
import spacy nlp = spacy.load('en_core_web_sm') def lemmatize_text(text): doc = nlp(text) return [token.lemma_ for token in doc] lemmas = lemmatize_text("I am running in the park") # 결과: ['I', 'be', 'run', 'in', 'the', 'park']
- 임베딩 (Embedding)
- 목적: 텍스트를 숫자 형태로 변환
- 작업:
- 단어를 고유한 정수 ID로 매핑
- 예시 코드 (Keras 사용):
1 2 3 4 5 6 7
from tensorflow.keras.preprocessing.text import Tokenizer texts = ["Hello how are you", "I am fine thank you"] tokenizer = Tokenizer() tokenizer.fit_on_texts(texts) sequences = tokenizer.texts_to_sequences(texts) # 결과: [[1, 2, 3, 4], [5, 6, 7, 8, 4]]
- 의도 분류 라벨링 (Intent Classification Label Encoding)
- 목적: 의도 레이블을 숫자로 변환
- 작업:
- 각 의도에 고유한 숫자 할당
- 예시 코드 (scikit-learn 사용):
1 2 3 4 5 6
from sklearn.preprocessing import LabelEncoder intents = ['greeting', 'farewell', 'query', 'greeting', 'query'] le = LabelEncoder() encoded_intents = le.fit_transform(intents) # 결과: [0, 1, 2, 0, 2]